
Ever your project got stuck in between because the limit of AI tools like Claude, Codex or any other AI tool got over? Ever thought why this is happening? Further in this article we will be looking at why it happens and how can we have more chats.
The AI Bill Nobody Budgeted For
It's not just you whose limit are getting over and stuffs. All companies have switched to work with AI. Companies are providing premium versions of AI tool to staffs for more efficient works. There is a conversation happening right now in boardrooms at Microsoft, Uber, Shopify, Spotify and it is not about AI. It is about money. It is about why the AI bill keeps arriving like a costly surprise and why nobody quite knows how to make it stop.
JP Morgan has recently released a report with an uncomfortable title "AI Token Costs Are Eating Into Internet Profits". Spotify, ServiceNow, and Roku all cited AI as a significant source of rising operational expenses. The mood in the industry has shifted from how cool it is to use AI to is this money really worth spending. Only 14% of CFOs say they can see clear, measurable returns on their AI investments.
The dirty secret of the AI era is that most people using these tools are using them wrong. Not wrong in the sense that they get bad answers though they often do but wrong in the sense that they are paying for far more computation than any task requires. They are handing an AI a map when they only needed directions. They are asking a question in 400 words when 40 would have done the job.
Let's talk about prompting what it is, what tokens are, how they are priced, and why the difference between a well-written prompt and a sloppy one can mean the difference between a $40 bill and a $400 one for the exact same outcome.
What Is an AI Token? The Unit Behind Every AI Response and Every Bill
When you type a sentence to an AI model, it does not read your words the way you do. It does not even see letters. It sees numbers. To convert your words into numbers, it first breaks your text into small pieces called tokens.
Think of tokens as the AI's alphabet not letters, not words it's something in between. A common English word like the is a single token. A complex word like tokenization might be three tokens: "token", "iz", and "ation". A space is often attached to the following word. Punctuation is its own token. Roughly 100 tokens is about 75 words in English.
Let's come to discuss about wallet. The AI we use is not free at all. AI Companies charge us per token that we enter in the prompt (input token) and the results that we get as response (output token). All input and output tokens are measured and usually the output tokens are two to four times more than that of input tokens. In the current time (June 2026), GPT-4o charges $5 per million input token and about $15 per million output tokens. Claude Sonnet charges around $3 per million for input tokens and $15 per million for output tokens. There are some lightweight models like GPT-4o mini or DeepSeek V3 which costs as low as $0.14 per million to $0.15 per million input and under $1 per million outputs. A million token is roughly about 750000 words which is around ten novels. If a staff of a company is firing poor prompts like repeats the contents, out of point contents or including unnecessary examples, this will lead to loss of tokens and burning money just like burning money to send a lot of texts on telegraph to your friend in 19th century.
Why the AI companies cost so much? Tokens are also the AI's processing, understanding, information storing limit and not just the billing unit. Every model can only hold so much text in its working memory at once. This is called the context window. GPT-4 Turbo holds about 128,000 tokens. Claude 3 holds around 200,000. Once you exceed that window, the AI will forget the conversation. It is just like a call getting dropped multiple times and after multiple drop you and your friend forget the conversation. Bloated prompts do not just cost more they also crowd out the important context.
The AI Cost Crisis: How Microsoft, Uber, and a $1.3 Million Monthly Bill Changed Everything
In 2024, enterprise AI felt like the future. Companies bought subscriptions, rolled out tools and let their engineers loose with unlimited access to the best model's money could buy. Everyone was assuming that AI would become cheaper over time so they did not think cost management was a upcoming issue in the recent time.
The assumption was wrong. Microsoft recently cancelled its developers access to Anthropic's Claude Code programming assistant with plans to move them to its internal Copilot CLI tool by end of June 2026. As the issue came to notice at the end of financial year, many people thought that cost-cutting was the reason. It became a major issue as Microsoft which is the OpenAI's largest investor also cut back on rival AI subscription at the same time.
Uber's Chief Operating Officer (COO) Andrew Macdonald put the broader problem plainly on a podcast saying "if you cannot see how much valuable functionality AI has helped you push to users, it is even harder to justify the token cost". The admission reflected a deeper dilemma that every enterprise is now wrestling with. Individual productivity gains from AI tools do not automatically translate into company-level revenue growth. Individual benefit is not the same as corporate benefit.
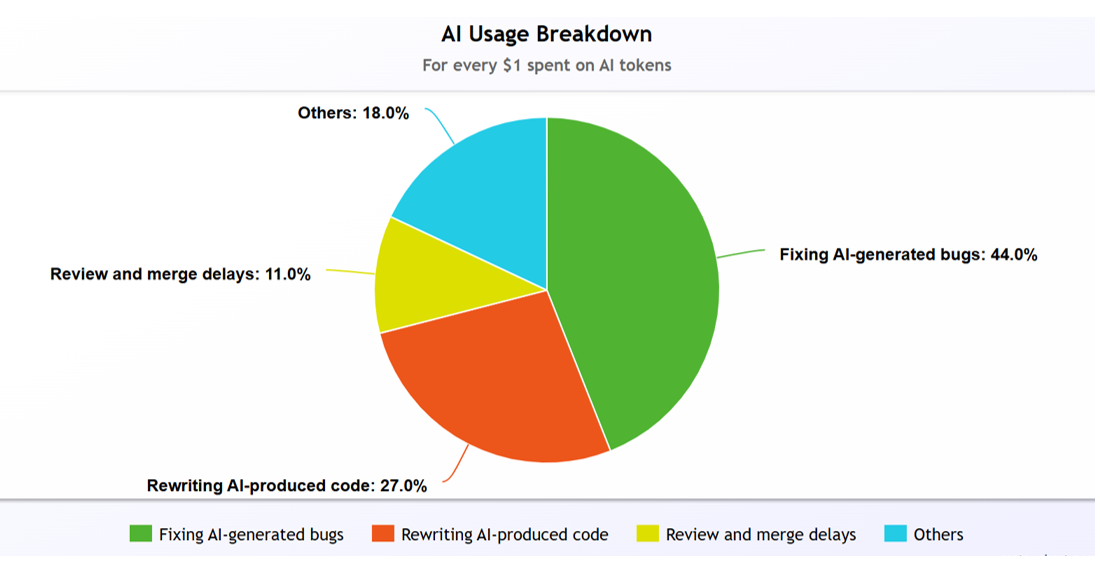
A study of 2,444 companies found that for every dollar spent on AI tokens, 44 cents goes toward fixing bugs generated by AI, 27 cents toward rewriting AI-produced code, and 11 cents toward review and merge delays. That is 82 cents of every AI dollar spent cleaning up after AI. A story from one team that serves as a warning to others. Peter Steinberger the creator of OpenClaw reported that his team spent more than $1.3 million in token costs in a single month. It was not because they were doing something extraordinary but it is because nobody had bothered to think carefully about how they were prompting.
Goldman Sachs has estimated that agentic AI where the model takes actions and uses tools autonomously could increase token consumption by over 24 times in the coming years. Gartner predicts that even as individual token costs fall, the sheer explosion in how many tokens people use will more than offset those savings. The math is simple and brutal as cheap tokens multiplied by reckless usage still produces a very high bill.
What Is AI Prompting? The Skill That Determines What You Pay and What You Get
A prompt is simply whatever you send to an AI model. It can be a question, instruction, a text that you need summarized, code you need to debug. The model cannot say the difference. It matches pattern against everything it has ever seen and generates the most statistically related continuation of the input.
Do you remember the Ghibli studio art trend when everyone was creating the Ghibli studio style images. These images cause over token usage and caused ChatGPT to go down. What makes prompting an art and increasingly a discipline with its own methodology is that the same question, framed differently, can produce very different results in terms of quality, accuracy, and cost. A vague prompt produces a vague answer. A precise prompt produces a precise answer. A well-structured prompt can produce a useful answer in 200 tokens. A bad prompt may produce a wrong answer in 600 tokens and then you pay again for the revision.
The history of prompting as a practice is very short. Before 2022, it was essentially the province of machine learning researchers who knew what they were doing. Then ChatGPT was launched in November 2022 and overnight, millions of people found themselves trying to get useful things out of a system that rewarded clarity and punished vagueness. Prompt engineering briefly became a job title before it became simply a skill everyone needed.
The people who prompt well are not necessarily the most technical. They are the most precise. They have the habit of questioning themselves what, exactly, do I want? And then they write that down properly before hitting send. The people who prompt badly are often the most comfortable with AI. They have gotten friendly with it. They forget it has no memory, no intuition about their preferences, and no idea they are in a hurry. Every conversation starts from zero. Every prompt is a complete instruction set. Or it should be.
Good Prompts vs Bad Prompts: Real Examples That Show the Token Cost Difference
Let us get concrete. Here are three pairs of prompts for common tasks one wasteful, one efficient. The token counts are real. The quality difference is stark.
Writing a product description. The bad version: Hey! I need some help writing a product description for my website. I'm selling a coffee maker. It's a really nice coffee maker, it brews fast, it has a timer, it keeps coffee warm. Can you write something good for my product page? Maybe something that would make people want to buy it? It should sound professional. Thanks! That is roughly 78 input tokens. The output will be 200 to 300 tokens of generic cheerfulness that will need two or three revision rounds to be usable.
The good version: Write a 50-word product description for a premium coffee maker. Features: 4-minute brew time, programmable timer, 2-hour keep-warm. Tone: confident, minimalist. No exclamation points. No filler phrases like 'perfect for.' That is around 42 input tokens. The output will be 55 to 70 tokens, on-spec, and usable immediately. The difference is not about being cold or robotic. It is about being clear about what you actually want.
Debugging code. The bad version: my code isn't working, I've been trying to fix it for hours, here's the whole file, can you find what's wrong and help me understand the issue? Also if you see any other improvements you could suggest that would be great too. The phrase also if you see any other improvements is the killer. Open invitations to elaborate are to AI what an open bar is to a wedding guest they will always take more than you expected.
The good version: Python 3.11. This function raises Key Error on line 14 when input dict is empty. Find and fix the bug only. Return: corrected function plus one-line explanation. Then paste only the relevant 20-line function, not the entire file. This takes roughly 85 input tokens and produces 60 to 90 usable output tokens. No tangents, no unsolicited suggestions, no lecture on coding best practices.
Summarizing a legal document. When the source document is large, you cannot shrink the input much. The contract is what it is. But you can absolutely control the output. Instead of asking: could you read through it and tell me what it says? Try: Summarize this vendor agreement. Return only: payment terms, liability caps, termination clauses, any unusual or risky provisions. Max 200 words total. Plain English. The same 10,000-token document input produces either a 500-token rambling narrative or a 200-token structured answer, depending entirely on whether you specified what you needed.
AI Prompting Methods That Actually Work: Zero-Shot, Few-Shot, and Chain-of-Thought Explained
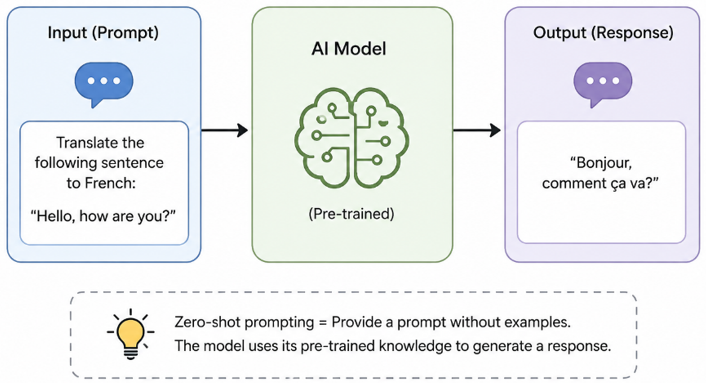
Researchers and practitioners found some prompting approaches that are tested, documented and are proven in production. Zero-shot prompting means asking the model to do something without giving it any examples. It works well for clear and straightforward tasks but it fails badly for tasks with unusual formats. It is the cheapest approach in tokens but it requires your instruction to be extremely precise.
Zero-shot prompting
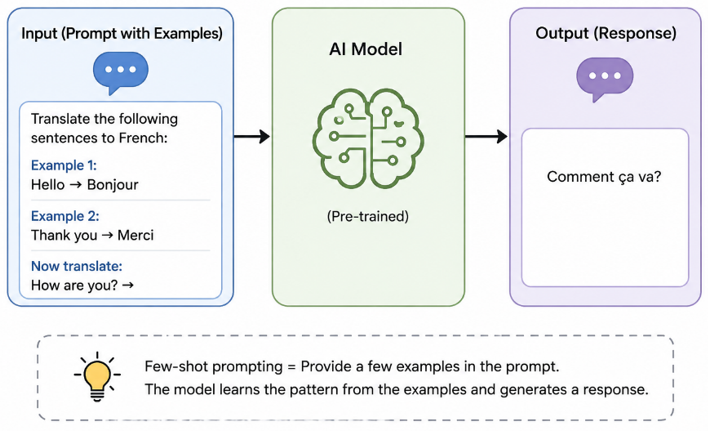
Few-shot prompting means giving the model one, two or three examples of exactly what you want before asking it to produce more. This is powerful for tasks where the shape of the output matters like data extraction, specific writing styles or custom analysis formats. The tradeoff is that each example costs tokens. Two examples at 100 tokens each means 200 extra tokens on every single call. Use only as many examples as needed to establish the pattern.
Few-shot prompting
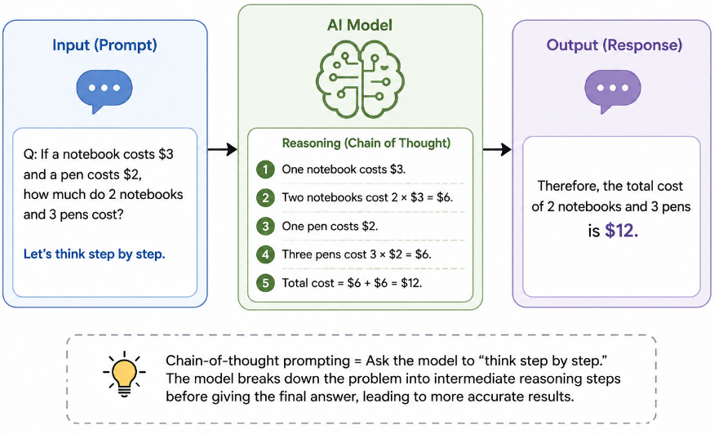
Chain-of-thought prompting involves adding think step by step or reason through this before giving your answer. It significantly improves performance on complex reasoning tasks. The tradeoff is that output tokens increase substantially if you expect three to five times more output. Use this only when accuracy matters more than cost which is often true for consequential decisions and rarely true for content generation.
Chain-of-thought prompting
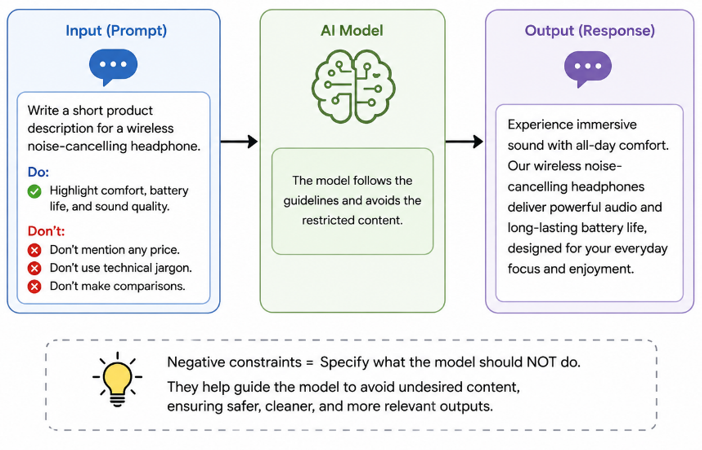
Negative constraints are perhaps the most underused technique. Here we tell the model what not to do is as important as telling it what to do. Do not include headers. Do not explain your reasoning. Do not use bullet points. Do not add caveats or apologies. Each of these negatives eliminates a whole category of output tokens that add length without adding value. Most AI models are trained to be thorough and polite. This is not always what you want. Give explicit permission to be brief and to the point.
Negative constraints
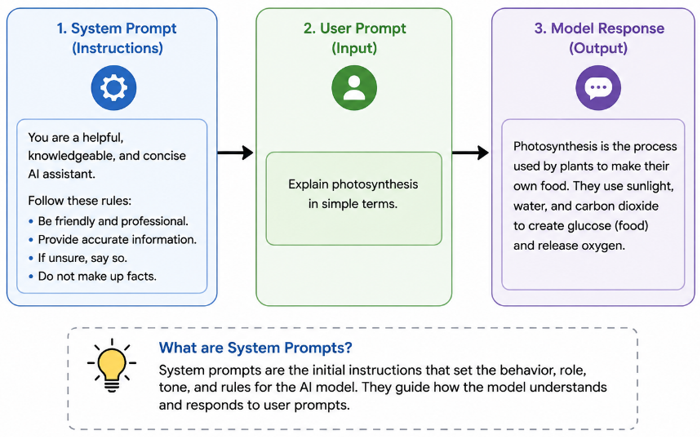
System prompts are available in most AI APIs and are instructions that live at the top of every conversation and tell the model how to behave. A good system prompt is a one-time investment where you pay for those tokens once but they shape every response that follows. Companies that have built tight, precise system prompts often see dramatic reductions in output word count because they have told the model once and clearly to be concise and to stop generating the words that are not required.
System Prompts
What do you think which prompt will you use to generate multiplication table? Will you give some examples as few shorts? Or use chain of thoughts by explaining if 7 is multiplied to 5 how 7 is added 5 times? For a multiplication table, zero-shot prompting with negative constraints wins every time. The model already understands multiplication it just needs no examples like few-shot, no step-by-step reasoning like chain-of-thought. Both would only add unnecessary tokens without improving the output. A simple instruction like "Generate the multiplication table of 7 from 1 to 10. Return only the table. No explanations." gets the job done in under 20 tokens. Chain-of-thought would produce paragraphs of arithmetic working. Few-shot would waste tokens on examples the model never needed. The lesson is simple: the best prompt matches the complexity of the task - and a multiplication table is not a complex task.
Why AI Prompt Efficiency Matters Beyond Cost: Speed, Quality, and Environmental Impact
The obvious reason to care about token efficiency is money. A team that trims its average prompt from 600 tokens to 300 tokens, and its average response from 400 tokens to 200 tokens, has halved its AI bill. At scale hundreds of users, thousands of daily requests that is real money, not theoretical savings. Companies that have routed tasks intelligently, reserved expensive models for complex reasoning, and used cheaper models for simple classification have cut their AI spending by 60 to 90 percent without sacrificing quality.
Faster responses are a second reason. Every token the model generates takes time. Not much time individually but in a production application where users are waiting or latency compounds. A model generating 200 tokens is faster than one generating 800 tokens. In agentic systems where AI calls trigger more AI calls the difference between a 3-second response and a 12-second one determines whether a product feels alive or frustrating.
Counterintuitive Prompting
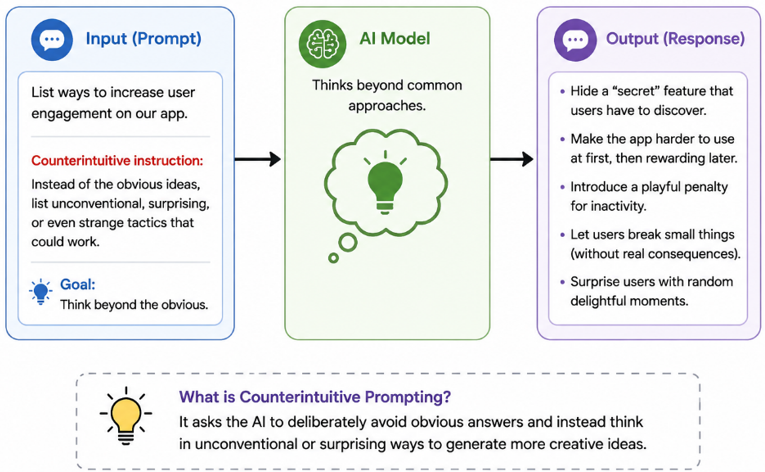
Better quality is the counterintuitive one. Shorter and more constrained prompts often produce better answers than long and less meaningful ones. When you give a model too much context especially context that is not relevant you dilute its attention. Language models have a phenomenon called lost in the middle where they attend more strongly to the beginning and end of a prompt than to what is buried in the center. A 4,000-token prompt where the critical instruction is on page two is worse than a 200-token prompt where the instruction is front and center.
Then there is the environmental dimension which almost never comes up in discussions of token efficiency. Every token a language model generates requires electricity to power the data centers processing it. Google, Oracle, and Microsoft have all recently extended their data center hardware lifespans to six years rather than the usual three, a direct response to the infrastructure cost of the AI boom. Token efficiency is, in a real sense, energy efficiency. The same principle that makes your prompt cheaper makes it greener.
How to Write Better AI Prompts: The Brief That Saves Time, Money, and Tokens
The word prompting will probably fall out of fashion. In ten years we will not call it prompting any more than we call it typing search terms when we use Google. It will just be communication a particular mode of communicating with systems that can reason.
But the underlying skill, the ability to express clearly what you want in a form a machine can act on efficiently will only become more valuable. As AI becomes more autonomous, as agents start making decisions on our behalf, the prompts we write today become the instructions that shape those decisions tomorrow. A wrong instruction to an autonomous agent is not just a token problem. It is a judgment problem.
The companies that figured out how to use AI cheaply and well did not achieve this with better technology. They achieved it with better thinking, better questions and more precise briefs. Microsoft and Uber are pulling back not because AI does not work but because nobody thought carefully about how to use it. The technology did what it was asked to do. The problem was in the asking.
The companies that figured out how to use AI cheaply and well did not achieve this with better technology. They achieved it with better thinking, better questions and more precise briefs. Microsoft and Uber are pulling back not because AI does not work but because nobody thought carefully about how to use it. The technology did what it was asked to do. The problem was in the asking.
The seven habits that make the biggest practical difference are
- Specify the output format before the task.
- Add length constraints to every content prompt.
- Remove word are not needed that cost tokens and provide nothing.
- Include negative constraints such as do not explain your reasoning.
- Only paste what is relevant and isolate the problem.
- Build a library of tested prompts for your most common tasks and reuse them.
- Treat output tokens as more expensive than input tokens because they are.
The Future of AI Prompting: From Manual Instructions to Autonomous Goal-Setting
Prompting has gone from an unclear research idea to a skill used by millions of people in just a few years. The early breakthrough came with Chain-of-Thought prompting, introduced by researchers at Google and published at NeurIPS 2022, Wei et al., NeurIPS 2022 which showed that asking a model to work through intermediate steps rather than jump straight to an answer which dramatically improved its performance on complex reasoning tasks. This was followed by an equally striking discovery by Kojima and colleagues, also at NeurIPS 2022, Kojima et al., NeurIPS 2022 who found that simply adding the phrase "Let's think step by step" could push a model's accuracy on arithmetic problems from the teens up to 70–80%, without any training examples at all.
These two papers showed the world that how you talk to an AI matters largely and the field has never looked back.
Today, the research has moved well beyond asking models to think step by step. Wang and colleagues proposed Self-Consistency, Wang et al., 2022 which generates multiple reasoning paths and picks the most common answer like taking a vote. Yao and colleagues introduced Tree of Thoughts at NeurIPS 2023, Yao et al., NeurIPS 2023 allowing models to explore branching paths the way a person thinks through a hard problem. Besta and colleagues pushed further with Graph of Thoughts, Besta et al., 2023 connecting AI reasoning in flexible networks rather than linear chains, improving sorting quality by 62% over Tree of Thoughts while cutting costs.
On the action side, ReAct (ICLR 2023) Yao et al., ICLR 2023 taught models to reason and act in one loop like searching, reading, and updating their thinking in real time. Reflexion Shinn et al., 2023 added another layer where models now write down what went wrong after each attempt and use it as a guide for the next try, improving accuracy by roughly 20 points on multi-hop tasks without changing any model weights. The frontier is now shifting toward AI that writes its own instructions. Automatic Prompt Engineering (APE) proposed by researchers at Stanford and Google, Zhou et al., 2022 showed that model-generated prompts can outperform many human-written ones. PromptAgent accepted at ICLR 2024, Wang et al., ICLR 2024 frames prompt optimization as strategic planning, reaching expert-level performance on specialized tasks.
Multi-agent frameworks where different models take on different roles, critique each other, and collaborate are producing results no single prompt-response cycle can match. Research on Multi-Agent Reflexion found that separating the roles of acting, diagnosing, and critiquing across agents improved code-generation accuracy by over six points compared to a single model working alone. MAR, 2025 The scope ahead is wide.
Researchers are building systems that infer user intent, retrieve context automatically and construct prompts behind the scenes so users just describe a goal and the system handles the rest. But this does not mean prompting will disappear. Just as search engines never eliminated the need for a good question, autonomous AI will not eliminate the need for clear thinking. The skill of expressing goals, constraints and priorities precisely will stay valuable as it will just live at a higher level. The future of prompting is not about longer instructions. It is about communicating more clearly and building systems sharp enough to act on that clarity.
AI Prompting in 2026: What Every User and Business Needs to Know Before Their Next Prompt
In 1918, William Strunk said his students "omit needless words". He had no way of knowing he was also describing the economics of a technology that would not exist for another hundred years. Needless words cost money now. The advice remains the same.
Every company using AI today is paying a bill they do not fully understand. Tokens are the invisible units that power every AI response that are quietly draining budgets, slowing teams and delivering returns that few finance leaders can measure. JP Morgan recently flagged AI token costs as a direct threat to internet-sector profits and only 14% of CFOs report clear returns on their AI investments. But the problem is rarely the technology itself. It is the way people use it. This article breaks down what tokens are, why they cost what they do and how smarter prompting changes everything.
So that's all from me about prompting techniques and how can we reduce costs. I hope you gained from this article and help for using budgeting techniques. If you have any more suggestions or something to discuss about you may connect with me on LinkedIn or email me from my website.

Aadarsh Senapati
AI enthusiast · Writer · Developer
Bhubaneswar, Odisha, India
Rate This Article
Leave a Comment