Get Full Article and Source Code
Download py file and full article which includes step by step guide.
What is RAG?
Retrieval-Augmented Generation or RAG is one of the most impactful architectural patterns in modern AI development. If you have ever asked an AI assistant a question about a document it has never seen, you already know the core problem is the model will either hallucinates and provide wrong answer or it admits it does not know. Imagine you ask your LLM “who is the CR of your class”, LLM will either provide some unrelated answer or reply like “I don’t know”. RAG solves the problem of both failure modes simultaneously by giving the model a structured, searchable memory it can consult before generating a response. Imagine now you provide a detailed document about your class. So, after reading the document LLM can provide the proper answer about “who is the CR of your class”.
Think of RAG like this, instead of asking a brilliant but forgetful professor a question and hoping they remember the relevant details, you hand them a stack of the most relevant pages from the right textbook before they answer. The professor (Large Language Model) is still the reasoning engine, but their answer is now anchored in real, retrieved, up-to-date information rather than stale parametric memory.
This distinction matters enormously in practice. A base LLM trained on data up to a certain date cannot answer questions about events that happened after that cutoff, cannot reason about private internal documents, and cannot cite sources for its claims. RAG overcomes all three limitations in a single architectural move.
Why Has RAG Become the Go-To Architecture?
According to industry surveys, RAG is now used in over 60% of enterprise LLM deployments. Customer support bots, legal document Q&A tools, medical knowledge assistants, research summarisers, and internal knowledge bases are all powered by some form of RAG. Learning to build one from scratch is arguably the single highest-ROI skill for any developer entering the AI field in 2025.
The business case is equally compelling. Before RAG, enterprises had two options, fine-tune a model on their proprietary data (expensive, requires ML expertise, needs retraining every time data changes) or prompt-engineer a base model with document context manually (limited by context window size, no scalability). RAG provides a third path with a dynamic, scalable retrieval layer that keeps the model's knowledge fresh without retraining.
RAG vs Fine-Tuning vs Prompt Engineering
It is very important to know when which tool is important and which tool to be used when. Looking deep into the tools, lets see which tool to use when.
| Model | When to use? |
|---|---|
| Fine-Tuning | When data don’t change frequently, Changing model behaviour/style, domain-specific reasoning patterns, latency-sensitive tasks |
| Prompt Engineering | Simple tasks, small amounts of context, rapid prototyping |
| RAG | Data changes frequently, large document collections, need for source citation |
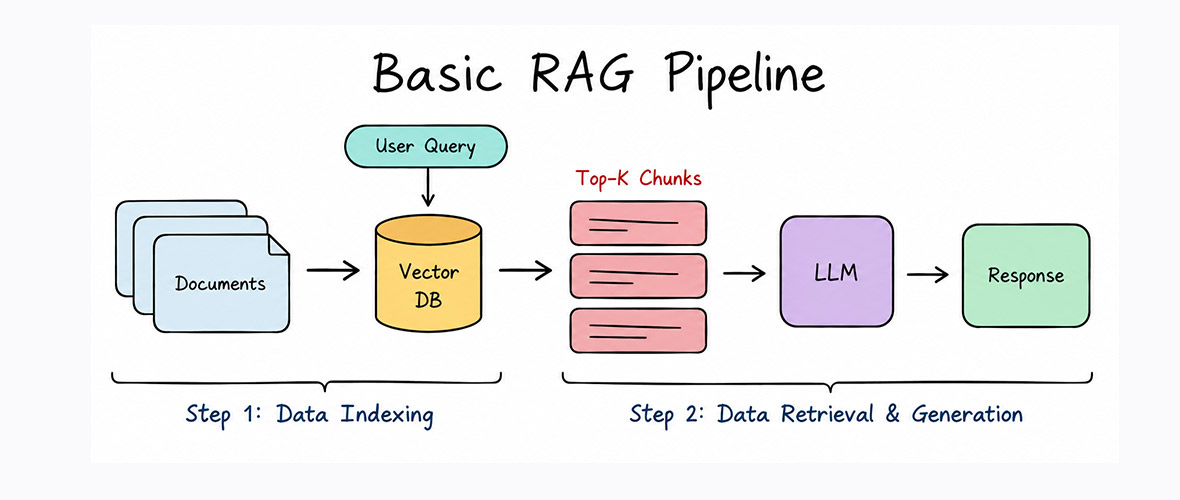
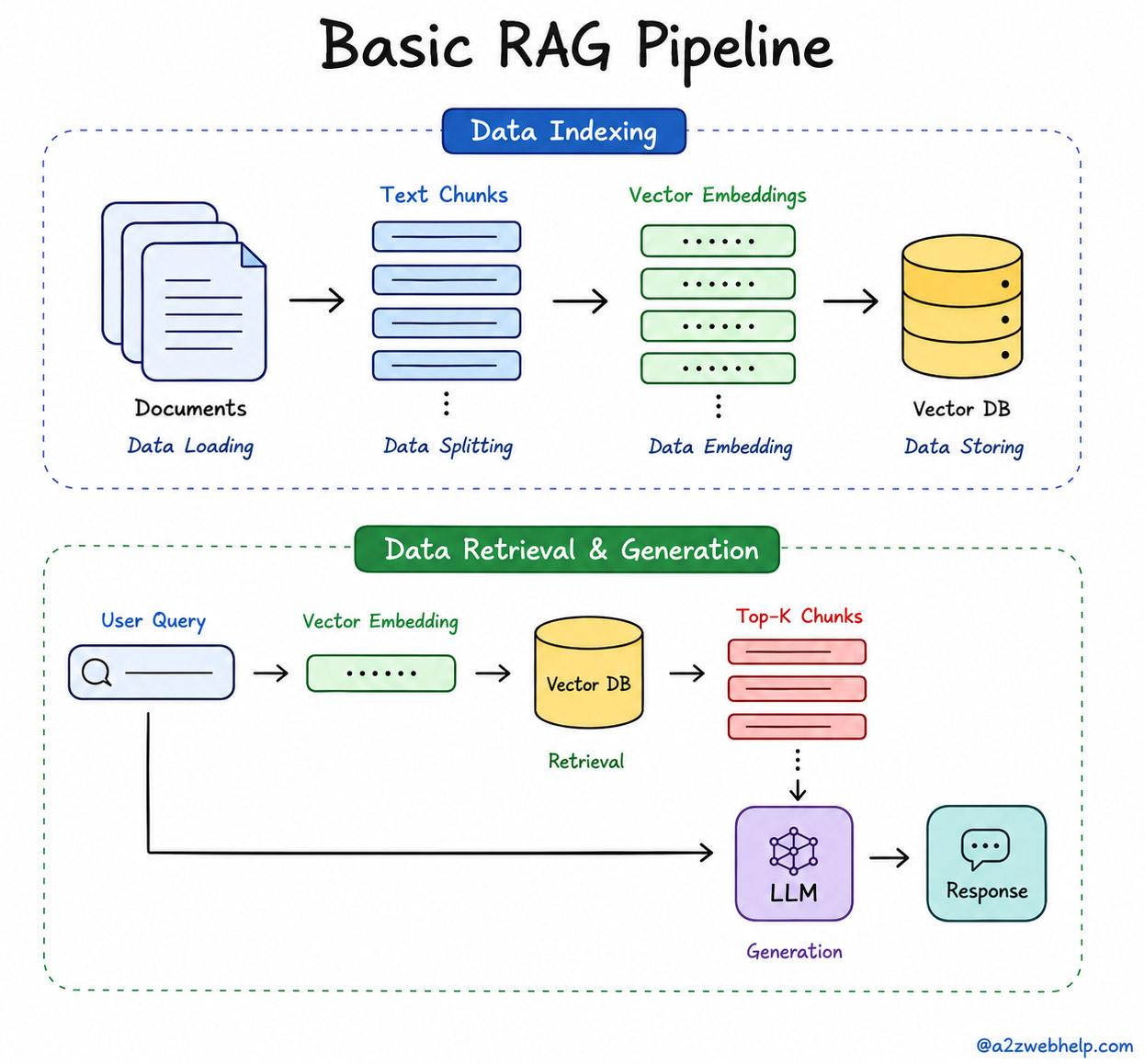
RAG is not a single library or a single API call. It is an architecture where a pattern that connects document loading, chunking, embedding, vector search, and language model inference into a coherent, composable pipeline.
Real World Use Case of RAG
To understand deeply into RAG system lets look into 5 real world use case of RAG:
- Legal documents: In the field of law, if we create a RAG system and add thousands of cases we can get the answer about every question related to the cases in natural languages with the clauses it uses.
- Medical field: Many hospitals provides RAG systems for doctor to get more information about clinical guidance and research papers to provide better care to patients.
- Customer support automation: SaaS companies build RAG chatbots over their documentation and ticket history so the bot can answer novel support questions by retrieving the most relevant help articles.
- Internal knowledge bases: companies connect RAG to their Confluence, Notion, or SharePoint workspaces so employees can ask HR, engineering, and policy questions in natural language.
- Research summarisation: academic institutions use RAG to let researchers query a corpus of papers and get synthesised answers with citations, dramatically accelerating literature reviews.
Building Chatbot using RAG Series
Get Full Article and Source Code
Download py file and full article which includes step by step guide.

Aadarsh Senapati
AI enthusiast · Writer · Developer
Bhubaneswar, Odisha, India
Rate This Article
Leave a Comment